搜索引擎工作原理一个SEO从业者应该了解的基础课程,但是有人却说搜索引擎工作原理对于新手来说是不容易理解的,因为工作原理太抽象,而且搜索引擎的变化无常,无论谁都不能真正认识搜索工作原理。那么一个页面是如何被搜索引擎发现并收录的呢?下面
安庆网站优化的小编为您分析:
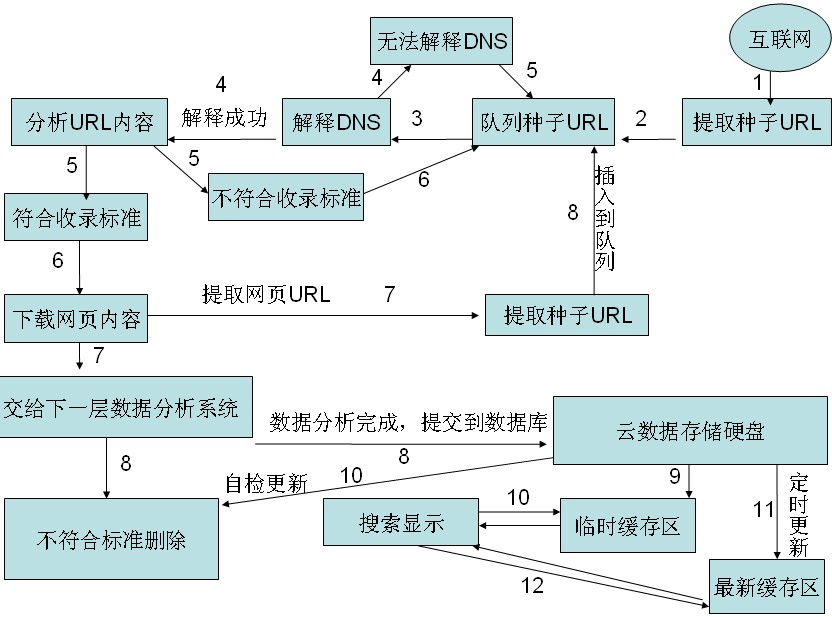
蜘蛛在整个互联网上爬行遇见你网站的一个URL,首先把URL提取出来根据网站权重和相关性插入到URL队列中,然后是判断你网站的这条URL是否能够解析成功,如果能解析成功,蜘蛛会爬到你网站,这里需要说一下,蜘蛛并不是直接去分析你网页的内容,而是去寻找你网站robots文件,根据你网站的robots规则判断是否抓取你这个页面,如果robots文件不存在,则会返回一个404错误,但是搜索引擎已经会继续抓取你的网站内容。
搜索引擎抓取了网页内容之后会对网页进行一个简单的判断是否达到了收录标准,如果不符合则继续把URL加入到URL 队列中,如果符合收录就会下载网页内容。
当搜索引擎拿到下载网页内容的时候,会提取出页面上的URL,继续插入到URL队列中,然后把页面上的数据,进行进一步分析,判断网页内容是否达到收录标准,如果达到收录标准则把页面存储到硬盘中。
当用户搜索某个关键词时,搜索引擎为了减少查询时间,将一部分相关性比较高的内容放到临时缓存区,大家都知道从计算机的缓存中读取数据,比在硬盘中读取数据快很多。所以搜索引擎只将缓存中的一部分显示给用户。被存储在硬盘中的页面,搜索引擎会根据网站权重定时对其进判断是否有更新,是否达到了放入缓存区的标准,如果搜索引擎在判断是否有更新的同时发现网站页面被删除或网页达不到被收录的标准也会被删除。
以上就是搜索引擎的页面收录原理,希望每一位seo人员都应掌握。